An Introduction To ESN
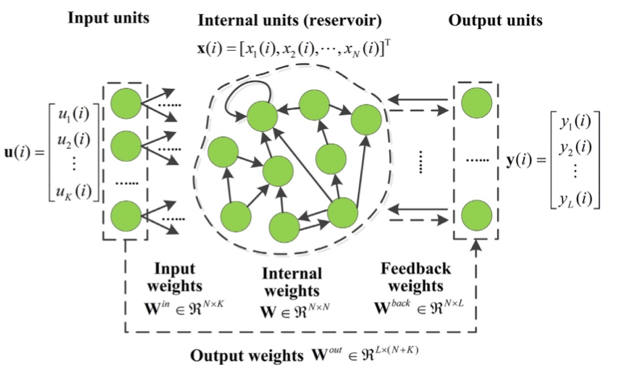 ESN
ESN
Intuitive
- An instance of the more general concept of reservoir computing.
- No problems of training a traditional RNN.
- A large reservoir of sparsely connected neurons using a sigmoidal transfer function(relative to input size, like 1000 units).
- Connections in the reservoir are assigned once and are completely random.
- The reservoir weights do not get trained.
- Input neurons are connected to the reservoir and feed the input activations into the reservoir - these too are assigned untrained random weights.
- The only weights that are trained are the output weights which connect the reservoir to the output neurons.
- Sparse random connections in the reservoir allow previous states to “echo” even after they have passed.
- Input/output units connect to all reservoir units.
- The output layer learns which output has to belong to a given reservoir state. - Training becomes a linear regression task.
Model
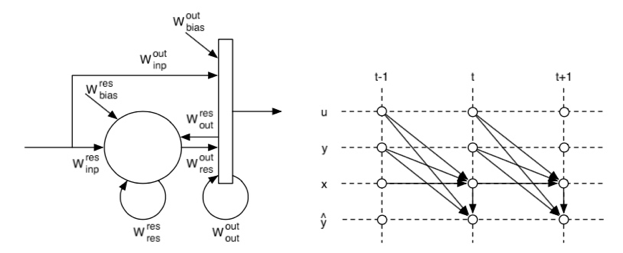 General model
General model
If we choose , we can write it like: Here:
- : input of time t.
- : weights of input layer.
- : num(input layer nodes)
- : leakage rate, control the update speed of reservoir nods.
- : reservoir state vector, recoding weight information of each reservoir node.
- : weighted adjacency matrix, usually a sparse matrix, use to generate.
- : (N,M) matrix, to change M-dim signals into reservoir computable format.
- : input signal, M-dim.
- : bias.
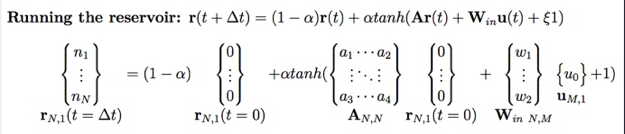 Running the reservoir
Running the reservoir
Here, all weights matrices to the reservoir () are initialized at random, while all connections to the output () are trained.
Train
1. Initial period
Update reservoir states
for t in range(trainLen):
u = input_signal[t]
r = (1 − alpha) ∗ r + alpha ∗ np.tanh(np.dot(A, r) + np.dot(Win, u) + bias)
if t >= initLen:
R[:, [t − initLen]] = np.vstack((u, r))[:, 0]
2. Training peroid
After collecting all these states, use ridge regression to train parameters. means target matrix
Test
To test reservoir:
S = np.zeros((P, testLen))
u = input_signal[trainLen]
for t in range(testLen):
r = (1 − alpha) ∗ r + alpha ∗ np.tanh(np.dot(A, r) + np.dot(Win, u) + bias)
s = np.dot(Wout, np.vstack((u, r)))
S[:, t] = s
u=s
Evaluation
RMS(root mean square) error.
Others
Echo state property
Input now has bigger effect on inner states than previous input or states.
That means it has to dismiss initial states when stable.
To meet ESP, the biggest eigenvalue of has to closer to 1 and less than 1.
(in program, make the max eigenvalue scales to 0.99 is ok)
Reference
- An overview of reservoir computing: theory, applications and implementations
- Introduction to reservoir computing
- ゼロから作るReservoir Computing
- Echo state network
Welcome to share or comment on this post: