2019 August 20 Machine Learning, Math
Bounding Box Regression
Bounding Box Regression
What is bounding box regression?
Find a f to map the raw input window P to real window G, we get G^. f(P)=G^,G^≈G 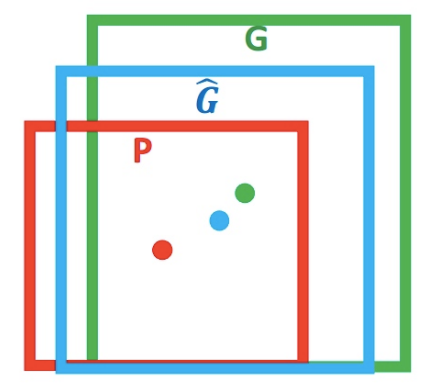 Figure 1
Figure 1
Why we need it?
To learn a transformation that maps a proposed box P to a ground-truth box G. You know, if we don’t define something to optimize, we cannot achive the goals.  Figure 2
Figure 2
What is IoU(Intersection over Union)?
Notice the green and red box below.  Figure 3
Figure 3
We use Bounding Box Regression to adjust that red window to approach green window. 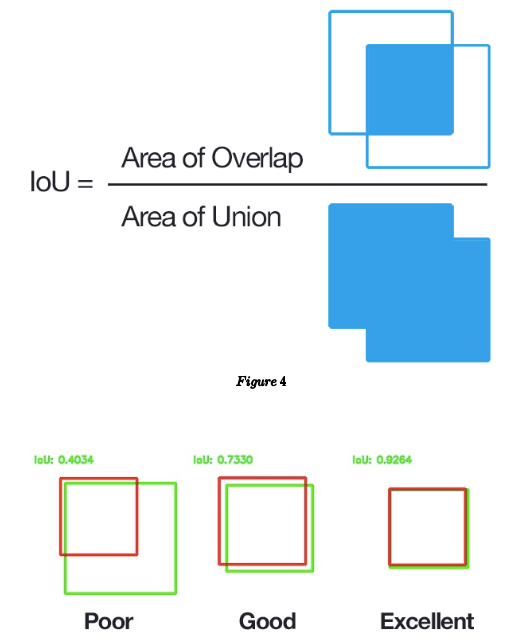 Figure 4
Figure 4
## get IoU according to box parameters
# import the necessary packages
from collections import namedtuple
import numpy as np
import cv2
# define the `Detection` object
Detection = namedtuple("Detection", ["image_path", "gt", "pred"])
def bb_intersection_over_union(boxA, boxB):
# determine the (x, y)-coordinates of the intersection rectangle
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# compute the area of intersection rectangle
interArea = (xB - xA) * (yB - yA)
# compute the area of both the prediction and ground-truth
# rectangles
boxAArea = (boxA[2] - boxA[0]) * (boxA[3] - boxA[1])
boxBArea = (boxB[2] - boxB[0]) * (boxB[3] - boxB[1])
# compute the intersection over union by taking the intersection
# area and dividing it by the sum of prediction + ground-truth
# areas - the interesection area
iou = interArea / float(boxAArea + boxBArea - interArea)
# return the intersection over union value
return iou
You see, it’s easy to calculate IOU using python.
How we find that function G^?
Target mapping f:
(Px,Py,Pw,Ph)=(G^x,G^y,G^w,G^h),(G^x,G^y,G^w,G^h)≈(Gx,Gy,Gw,Gh)
Core concept
- translation
- (Δx,Δy),Δx=Pwdx(P),Δy=Phdy(P) G^x=Pwdx(P)+PxG^y=Phdy(P)+Py(1)
- scaling
- (Sw,Sh),Sw=exp(dw(P)),Sh=exp(dh(P)) G^wG^h=Pwexp(dw(P))=Phexp(dh(P))(2)
That means, bounding box regression is to learning dx(P),dy(P),dw(P),dh(P), we can find that we could use d∗(P)=w⋆Tϕ5(P) to learn how to map ϕ5(pool5 features of proposal P) to d∗, which is a simple linear regression problem, and we can use the formula (1)-(2) to get G^.
G^ is forecast value, but we need G^ to be G. So we still need to find the difference between G and G^.
What’s the difference between G^ and G?
We want G^ to be as close to G as possible, that means, we need to find a bounding box input: features of proposal ϕ5 (CNN pool5 output) bounding box output: dx(P),dy(P),dw(P),dh(P). Then we can map P to G.
How to use the bounding box output to get G?
From above we can know that we could get G^ from dx(P),dy(P),dw(P),dh(P), not G. Notice, from P to G means: tx=(Gx−Px)/Pwty=(Gy−Py)/Phtw=log(Gw/Pw)th=log(Gh/Ph)
That means if we reduce the error between dx(P),dy(P),dw(P),dh(P) and t∗=(t∗∗x,ty,tw,th)), we can really map our P to G, because we have bounding box help use to learn the real t∗ for us. ⇒
We can reduce the loss function: Loss=i∑N(t∗i−WTϕ5(Pi))2 to accomplish our goal. Here ϕ5(Pi) means the input to bounding box.
Also to regularize the loss function, we can use: W∗=argminw,∑iN(t∗i−WTϕ5(Pi))2+λ∥w^∗∥2 and use gredient descent to get W.
Why we can use G^=WP?
When IoU > θ (like 0.6), we can think the transformation be a linear transformation, and use that function to adjust. tw=log(Gw/Pw)=log(PwGw+Pw−Pw)=log(1+PwGw−Pw) When Gw−Pw≈0, we think it as linear. x=0limlog(1+x)=x
Reference
Welcome to share or comment on this post: