The Easiest Introduction To Cross Validation
What is Cross validation?
Cross-validation is a technique that is used for the assessment of how the results of statistical analysis generalize to an independent data set. It’s a statistical method of evaluating and comparing learning algorithms by dividing data into two segments: one used to learn or train a model and the other used to validate the model. In typical cross-validation, the training and validation sets must cross-over in successive rounds such that each data point has a chance of being validated against. The basic form of cross-validation is k-fold cross-validation. Other forms of cross-validation are special cases of k-fold cross-validation or involve repeated rounds of k-fold cross-validation.
How we understand it?
Imagine one of your classmate yyxsb, we want to estimate whether he will come to school today or not. We have many data that he came to school or did’t in the past few months. As you know, if it rains, yyxsb may not come to school, but if he has any event, like has to submit his project review or has to present what he has done recently, he will have a good chance to go to school. There are many reasons that yyxsb don’t want to go to school.
Here, to simply the problem, we assume the main reasons are weather, school event, holidays (yyxsb may come to school even on holidays), and the target is to estimate if he will come today. We have a table of data that recorded if he came to school that day.
Then we can use some machine learning algorithms (like svm) to estimate if he will come on mon, tue, wen, thur, fri, sar, sun day.
Ok, first we test will he come to school on monday, we use 75% of all data, to train the model and 25% of all data to test the model. Then we got our model, and we input the reasons to test if he will come today. Today is sunny, no event, monday, the algorithms tells us that yyxsb will come! In fact, he indeed comes to the school. The model seems fits well. Say, accuracy is 100%.
Then, we use the same model on monday to test weather it work on other days or not, and we got not so bad result on tue/wen/thur day.
Naive, naive, naive (Important things need to be repeated for three times). Things does not done, we will find that the model does not work well(may be bad, accuracy 30%) on fri/sat/sun day! Here we say the model overfitting.
Because fri/sat/sun day may be different than other days, he may plan to chase girls or go to netbar and our input reasons don’t consider these things.
If we can average the accuracy reselt tested for different days, then we know can get a accuracy, the example above is (100% * 4+30% * 3)/7 = 70%. Seems not too bad. But we have to notice that the model we use does not fit well in fri/sat/sun day! Dare you use it to persuade others that yyxsb will come on fri day?
Ok, this model is not so good, then we shuffle the data, train another one. This time, we get a accuracy of [60%, 60%, 60%, 60%, 50%, 50%, 50%], then average accuracy is (60% * 4 + 50% * 3)/7 = 56%. Why we got a even lower accuracy? In this time, we average them, (70%+56%) = 63%, which seems more reliable.
Why the accuracy is different? Because the amount of data we use is small, then we may got very unbelievable result. For example, We found that yyxsb come to school everyday on last week, we may assume that he will also come to school everyday this week or yyxsb come to school everyday since he was five, and he will come to school this week everyday, which sentence is more reliable?
That means we cannot just believe our model by just one of the train test model.
So the question is: how can we get a compellent result that the average accuracy our model shows if yyxsb will come today?
First, let’s analyze why that phonomenon happens. yyxsb may have different action trend on different days, but if fact our model here assume that he have the same pattern every day! so there is no doubt that our model will fit so well on somedays while bad on other days. What caused that?– our test data contains too much information about somedays, while not other days. For example, our train data is mainly mon/tue/wen/thur, but test data are mainly fri/sat/sun, they have different patterns, so we will got very bad result.
Ok, we got the reseans, then the question is: how to solve that problem?
Since we can not believe just one train test result, then we just use many different train test models to get a average model, like figure 1.
We need to prevent some overfiting, then we need use cross validation like above, to choose good parameters for the model.
Also, if we want to try different algorithms, but we don’t know which is better, we can also use cross validation to get accuracy of all of them, then find a best algorithms to forcast if yyxsb will come to school.
How to make your grandmother understand cross validation?
Use the back ground above, we can tell your grandmother that because we only know that yyxsb came to school or not on the last week, we have 7 person to forcast weather yyxsb will come to school. For the first person A, we tell the man mon/tue/wen/thur/fri/sat data, then ask him to forcast if yyxsb will come on sunday, person A made a right forcast, 100% accuracy! For the first person A, we tell the man mon/tue/wen/thur/fri/sun data, then ask him to forcast if yyxsb will come on sartuday, person B made a wrong forcast, 0% accuracy! Similarly, we asked all of them to forcast one day this week, the accuracy is [100%, 0%, 0%, 100%, 100%, 0%, 100%, 100%].
Then we ask all of them to forcast any day that yyxsb will come to school. Their anwser is [0%, 100%, 100%, 100%, 0%, 0%, 100%, 0%] You can ask your grandmother, who will you choose? Of course we will average their forcast! That is cross validation, we need all man to see diferent data, and average their suggestions.
Why we need it?
- A methods to solve the problem of over fitting:
- We divide the data in multiple ways, and then statistical methods are used to find the average accuracy.The train data we use may be only fit some of the system, the idea is that once we have identified our best combination of parameters (in our case time and route) we test the performance of that set of parameters in a different context. for example, we use mon as test, others are train data, we may found parameters works well in mon/thur/fri, but if we use the same model to test other days, it may not work well in tue/wen, we want the parameters works well in tue/wen too, so if we use different test data, then average them, so we can avoid some overfitting!
- It makes us more confident to the model trained on the training set. Without cross-validation, our model may perform pretty well on the training set, but the performance decreases when applied to the testing set.
- To compare diffirent models:
- Different models may fit well for different data, we need a standard to compare them. We got the average accuracy, then we can compare them
How it works?
K-fold:
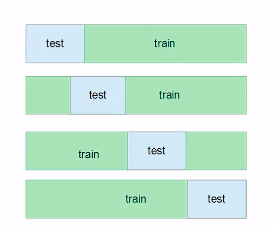 K-fold cross validation
K-fold cross validation
- Divide data into multiple chunks of train-test splits and get average accuracy
- The smaller the test, the better result we can get, but also takes longer(LOOCV)
Random subsampling:
- Randomly select test and train splits
# How to use k-folds
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
iris = load_iris()
dataInput = iris.data
dataOutput = iris.target
kf = KFold(n_splits=10,shuffle = True) # test data= all * 1/n_split
for train_index, test_index in kf.split(dataInput):
x_train,x_test = dataInput[train_index],dataInput[test_index]
y_train,y_test = dataOutput[train_index],dataOutput[test_index]
"""
here we can write our code to get our accuracy by different iteration(n_splits times), then get a average accuracy or we can use cross_val_score()function to finish all the work, like the code below
"""
The connections to ML algorithms
Often we can use cross validation and machine learning algorithms together, like CS + SVM/KNN, to get the best performance. It’s just a general data validation method, so we can use it in many machine learning algorithms.
Usage:
- use different machine learning algorithms, then compare the average accuracy, like:
# ignore import and data here kf = KFold(n_splits=10) clf_tree=DecisionTreeClassifier() scores = cross_val_score(clf_tree, X, y, cv=kf) avg_score = np.mean(score_array) - for one ML algorithm, choose the median parameters for the best performance, like:
# ignore import and data here X = inputdata y = outputdata # target kf = KFold(n_splits=10) clf_tree=DecisionTreeClassifier() # model 1 scores1 = cross_val_score(clf_tree, X, y, cv=kf) avg_score1 = np.mean(score_array1) svm=SVM() # model 2 scores2 = cross_val_score(svm, X, y, cv=kf) avg_score2 = np.mean(score_array2) print(avg_score1, avg_score2)Drawbacks
Need computing resource if the number of data is huge, so we seldom use it in Deep learning.
Summary
The key points are understdand how k-fold works, and why it works. Finally we can get a average accurcay to determine which model to use, or parameters to choose. Also, we have more confident on our method if we can use average accuracy to show our results.
Reference
- Cross Validation and Model Selection
- Cross-Validation in plain english
- 複数の機械学習ライブラリを一発で適応しちゃう方法
- Cross-Validation
Welcome to share or comment on this post: